ARIMA: el primer modelo que de verdad predice el futuro
En el capítulo anterior aprendiste a ver una serie temporal como la suma de tendencia, estacionalidad y ruido. Ahora viene la pregunta incómoda: ¿cómo usas eso para predecir?
La respuesta corta es: primero conviertes la serie en algo más predecible, luego eliges un modelo que aproveche la dependencia entre valores pasados y, finalmente, proyectas hacia delante. El modelo más clásico para hacerlo es ARIMA. No es el más moderno, pero entenderlo bien es como aprender a conducir con cambio manual antes de subirte a un coche automático: todo lo demás se entiende mucho mejor.
El supuesto que lo cambia todo: estacionariedad
Una serie es estacionaria si sus propiedades estadísticas —media, varianza y autocorrelación— no cambian con el tiempo. Visualmente, es una serie que parece “moverse alrededor de una media constante” sin una pendiente clara ni cambios de amplitud.
¿Por qué importa? Porque la mayoría de modelos clásicos asumen que el futuro se parecerá estadísticamente al pasado. Si la media sube sin parar, ese supuesto se rompe.
Hay un test muy usado para comprobarlo: el test de Dickey-Fuller aumentado (ADF). La hipótesis nula es que la serie no es estacionaria.
from statsmodels.tsa.stattools import adfuller
# La hipótesis nula: la serie no es estacionaria
resultado = adfuller(serie)
print(f"Estadístico ADF: {resultado[0]:.4f}")
print(f"p-valor: {resultado[1]:.4f}")
if resultado[1] < 0.05:
print("La serie es estacionaria (rechazamos H0)")
else:
print("La serie NO es estacionaria (no rechazamos H0)")Si tu p-valor es menor que 0.05, celebras: la serie es estacionaria. Si no, toca transformarla.
Diferenciación: quitando la tendencia
La técnica más sencilla para hacer estacionaria una serie es la diferenciación. Consiste en restar cada valor al anterior:
$$\Delta y_t = y_t - y_{t-1}$$
Si una diferencia no basta, puedes aplicar una segunda diferencia. En la práctica, rara vez necesitas más de dos.
# Primera diferenciación
serie_diff = serie.diff().dropna()
# Comprobamos de nuevo
resultado_diff = adfuller(serie_diff)
print(f"p-valor tras diferenciar: {resultado_diff[1]:.4f}")Tras diferenciar, la serie debería moverse alrededor de cero. Si aún tiene estacionalidad fuerte, también puedes diferenciar estacionalmente, restando el valor del mismo mes del año anterior.
# Diferenciación estacional: restamos el valor del mismo mes del año anterior
serie_diff_seasonal = serie.diff(12).dropna()
# Combinamos diferenciación regular y estacional
serie_diff_double = serie.diff().diff(12).dropna()
resultado_double = adfuller(serie_diff_double)
print(f"p-valor tras diferenciar regular + estacional: {resultado_double[1]:.4f}")Cuándo parar: si tras una o dos diferenciaciones el p-valor del ADF es menor que 0.05, ya tienes una serie estacionaria. No sigas diferenciando por inercia: cada diferenciación pierde una observación y puede introducir ruido.
ACF y PACF: los ojos del modelador
Una vez estacionaria, necesitas decidir los parámetros del modelo. Para eso usas dos gráficas:
- ACF (Autocorrelation Function): correlación de la serie con sus propios lags.
- PACF (Partial Autocorrelation Function): correlación con un lag eliminando el efecto de los lags intermedios.
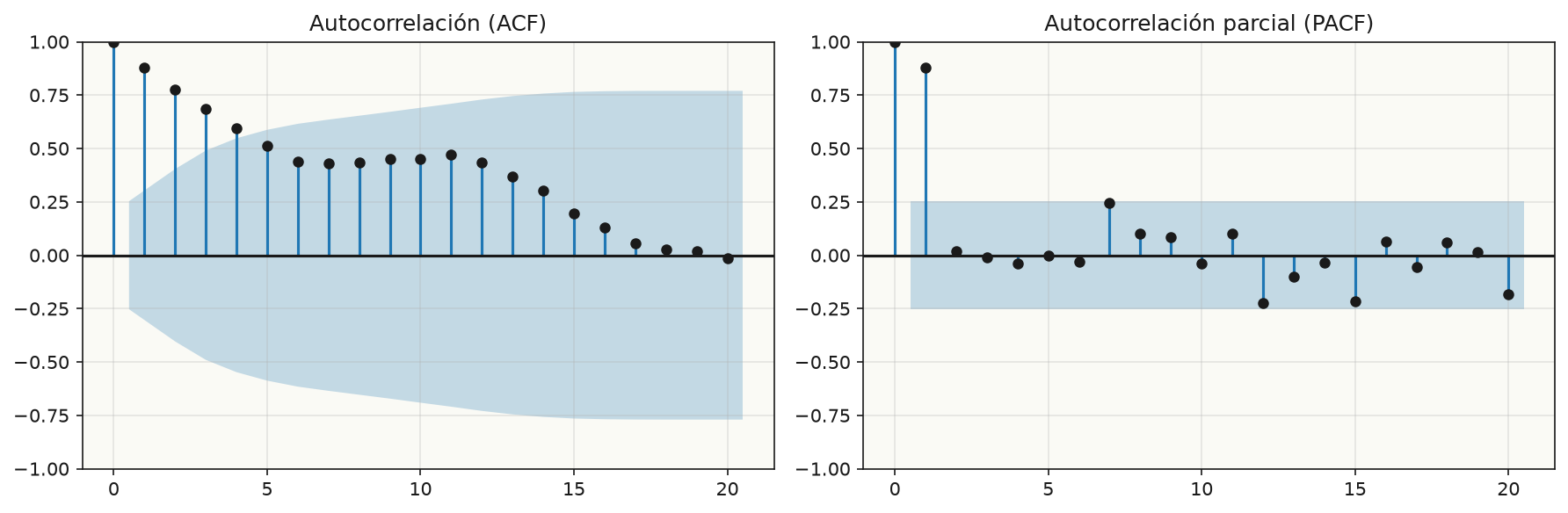
En la imagen puedes ver cómo la ACF decrece lentamente: es la señal típica de una serie no estacionaria o con tendencia. La PACF te ayuda a identificar el orden autorregresivo.
La regla mnemotécnica clásica es:
| Gráfica | Patrón | Indica |
|---|---|---|
| ACF | decrece gradualmente | Componente de promedio móvil (q) |
| PACF | corta bruscamente tras lag p | Componente autorregresivo (p) |
| ACF | picos en lags estacionales | Necesidad de diferenciación estacional |
No tomes estos cortes como dogma. Son una guía para empezar a explorar, no un procedimiento automático. Siempre valida con métricas como AIC o BIC.
Cómo funciona ARIMA
ARIMA son las siglas de AutoRegressive Integrated Moving Average. El modelo tiene tres parámetros:
- p: orden autorregresivo. Cuántos valores pasados influyen directamente en el actual.
- d: número de diferenciaciones necesarias para hacer la serie estacionaria.
- q: orden de promedio móvil. Cuántos errores pasados usas para corregir la predicción.
Un ARIMA(1,1,1) dice: “Diferencio una vez, y luego modelizo la serie diferenciada usando un valor pasado y un error pasado.”
En código, ajustarlo es directo:
from statsmodels.tsa.arima.model import ARIMA
# Dividimos en entrenamiento y test (últimos 12 meses)
train = serie.iloc[:-12]
test = serie.iloc[-12:]
# Ajustamos ARIMA(2, 1, 2)
modelo = ARIMA(train, order=(2, 1, 2))
resultado = modelo.fit()
print(resultado.summary())El resumen de statsmodels muestra muchos números, pero los más importantes son los coeficientes ar.L1, ar.L2, ma.L1, ma.L2 y sus p-valores. Si un coeficiente no es significativo, quizá tu modelo tiene más parámetros de los necesarios.
Generar pronósticos con intervalos de confianza
Una vez ajustado el modelo, puedes proyectar hacia delante. Lo más útil de statsmodels es que no solo te da una línea de predicción, sino también un intervalo de confianza. Eso es oro: te dice dónde esperas que esté el valor real, no solo un punto.
# Pronóstico para los 12 meses de test
forecast = resultado.get_forecast(steps=12)
prediccion = forecast.predicted_mean
intervalo = forecast.conf_int(alpha=0.05)
# Graficamos
plt.figure(figsize=(12, 6))
plt.plot(train.index, train, label="Entrenamiento", color="#1a1a1a")
plt.plot(test.index, test, label="Test real", color="#a8e6cf")
plt.plot(test.index, prediccion, label="Predicción ARIMA", color="#ffcc00")
plt.fill_between(
test.index,
intervalo.iloc[:, 0],
intervalo.iloc[:, 1],
color="#ffcc00",
alpha=0.3,
label="Intervalo 95%",
)
plt.legend()
plt.title("Predicción con ARIMA")
plt.show()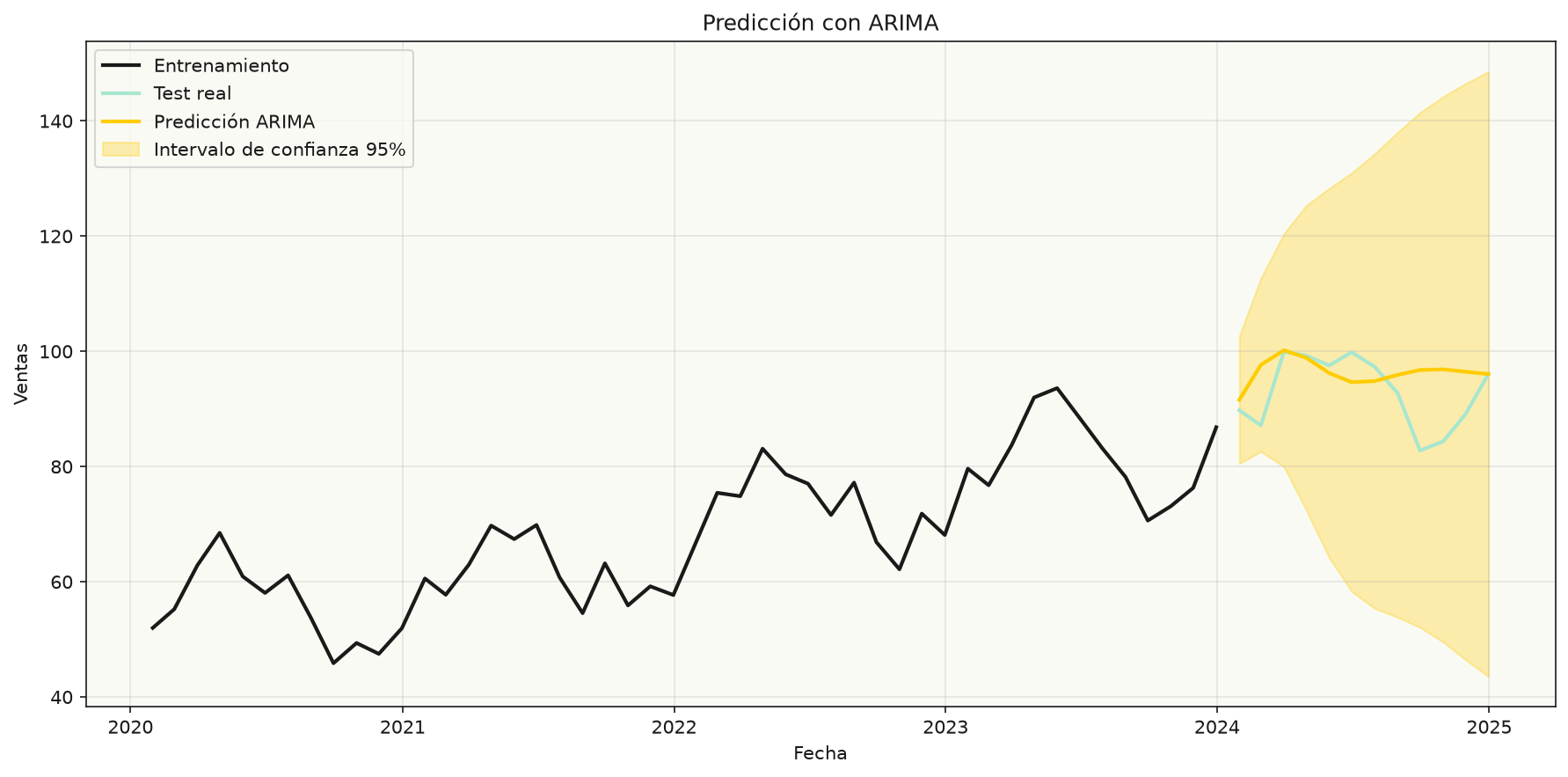
En la gráfica se aprecia cómo la predicción sigue la dinámica general de la serie. No es perfecta —nunca lo será—, pero captura tanto la tendencia como gran parte de la oscilación.
Métricas para evaluar el pronóstico
La gráfica es útil, pero necesitas números para comparar modelos. Las métricas más comunes son el MAE (error absoluto medio) y el RMSE (raíz del error cuadrático medio).
from sklearn.metrics import mean_absolute_error, mean_squared_error
mae = mean_absolute_error(test, prediccion)
rmse = mean_squared_error(test, prediccion, squared=False)
print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")| Métrica | Qué mide | Cuándo usarla |
|---|---|---|
| MAE | Error absoluto medio en las mismas unidades que la serie | Cuando todos los errores tienen la misma importancia |
| RMSE | Penaliza más los errores grandes | Cuando los errores grandes son especialmente costosos |
También es útil comparar contra un baseline ingenuo: predecir que el próximo valor es igual al último valor observado. Si tu ARIMA no mejora eso, algo está fallando.
# Baseline ingenuo: el último valor de train se repite para todo el test
baseline = pd.Series(train.iloc[-1], index=test.index)
mae_baseline = mean_absolute_error(test, baseline)
print(f"MAE baseline: {mae_baseline:.2f}")
print(f"MAE ARIMA: {mae:.2f}")Cómo elegir los mejores parámetros
Ajustar a mano p, d y q es didáctico, pero en proyectos reales conviene automatizar la búsqueda. Puedes entrenar varios modelos y quedarte con el que minimice el AIC (Akaike Information Criterion) o el BIC.
import itertools
mejor_aic = float("inf")
mejor_orden = None
for p, d, q in itertools.product(range(0, 4), range(0, 2), range(0, 4)):
try:
modelo = ARIMA(train, order=(p, d, q))
ajustado = modelo.fit()
if ajustado.aic < mejor_aic:
mejor_aic = ajustado.aic
mejor_orden = (p, d, q)
except Exception:
continue
print(f"Mejor orden: {mejor_orden} con AIC: {mejor_aic:.2f}")Cuidado con el overfitting. Un modelo con muchos parámetros puede ajustar muy bien el pasado y fallar estrepitosamente en el futuro. El AIC penaliza la complejidad, pero sigue siendo recomendable validar con un test set o con validación cruzada temporal.
Diagnóstico de residuos
Un buen modelo ARIMA debe dejar residuos que parezcan ruido blanco: media cero, varianza constante y sin autocorrelación. Si los residuos tienen patrón, el modelo aún no ha capturado toda la estructura de la serie.
# Residuos del modelo
residuos = resultado.resid
fig, axes = plt.subplots(2, 1, figsize=(10, 6), sharex=True)
# Serie de residuos
axes[0].plot(residuos, color="#1a1a1a", linewidth=1)
axes[0].axhline(0, color="#ffcc00", linestyle="--", linewidth=2)
axes[0].set_title("Residuos del modelo ARIMA")
axes[0].grid(True, alpha=0.3)
# Histograma de residuos
axes[1].hist(residuos, bins=20, color="#ffcc00", edgecolor="#1a1a1a")
axes[1].set_title("Distribución de los residuos")
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()Visualmente buscas dos cosas: que los residuos oscilen alrededor de cero sin patrones, y que su histograma se parezca a una campana. Para confirmarlo formalmente puedes aplicar el test de Ljung-Box:
from statsmodels.stats.diagnostic import acorr_ljungbox
ljung = acorr_ljungbox(residuos, lags=10, return_df=True)
print(ljung.head())Si los p-valores son altos (mayores que 0.05), no hay evidencia de autocorrelación residual y el modelo es razonablemente bueno.
Un paso más allá: SARIMA
Si tu serie tiene estacionalidad fuerte, ARIMA normal no es suficiente. Necesitas SARIMA (Seasonal ARIMA), que añade tres parámetros estacionales: P, D, Q y el período s.
from statsmodels.tsa.statespace.sarimax import SARIMAX
# SARIMA(1,1,1)(1,1,1,12) para series mensuales con estacionalidad anual
modelo_sarima = SARIMAX(train, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
resultado_sarima = modelo_sarima.fit(disp=False)
prediccion_sarima = resultado_sarima.get_forecast(steps=12).predicted_mean
mae_sarima = mean_absolute_error(test, prediccion_sarima)
print(f"MAE ARIMA: {mae:.2f}")
print(f"MAE SARIMA: {mae_sarima:.2f}")En series con estacionalidad clara, SARIMA suele reducir el error de forma notable. Es la extensión natural de ARIMA cuando los patrones se repiten cada cierto tiempo.
Limitaciones de ARIMA
ARIMA es potente, pero no es una varita mágica:
- No captura bien estacionalidades complejas sin la extensión SARIMA.
- No maneja múltiples series relacionadas —para eso están los modelos VAR.
- Es sensible a outliers y cambios estructurales.
- No incluye variables externas —si quieres añadir promociones o festivos, necesitas ARIMAX o modelos de ML.
Aun así, sigue siendo un excelente punto de partida. Muchas empresas usan ARIMA como benchmark antes de probar modelos más sofisticados.
Resumen y próximo paso
En este capítulo has aprendido a comprobar la estacionariedad con el test ADF, a diferenciar series temporales, a interpretar ACF y PACF, y a ajustar un modelo ARIMA con statsmodels para generar pronósticos con intervalos de confianza.
ARIMA es un modelo clásico, pero el mundo del forecasting ha evolucionado mucho. En el próximo capítulo veremos cómo usar machine learning —concretamente modelos basados en árboles— para predecir series temporales utilizando features de retardos, ventanas móviles y variables externas.